PII, PHI Masking - Presidio
Overview
| Property | Details |
|---|---|
| Description | Use this guardrail to mask PII (Personally Identifiable Information), PHI (Protected Health Information), and other sensitive data. |
| Provider | Microsoft Presidio |
| Supported Entity Types | All Presidio Entity Types |
| Supported Actions | MASK, BLOCK |
| Supported Modes | pre_call, during_call, post_call, logging_only |
Deployment options
For this guardrail you need a deployed Presidio Analyzer and Presido Anonymizer containers.
| Deployment Option | Details |
|---|---|
| Deploy Presidio Docker Containers | - Presidio Analyzer Docker Container - Presidio Anonymizer Docker Container |
Quick Start
- LiteLLM UI
- Config.yaml
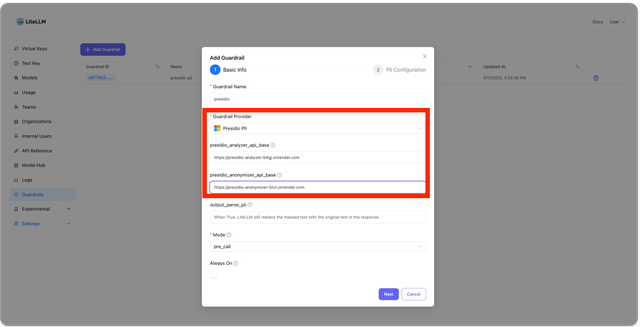
1. Create a PII, PHI Masking Guardrail
On the LiteLLM UI, navigate to Guardrails. Click "Add Guardrail". On this dropdown select "Presidio PII" and enter your presidio analyzer and anonymizer endpoints.
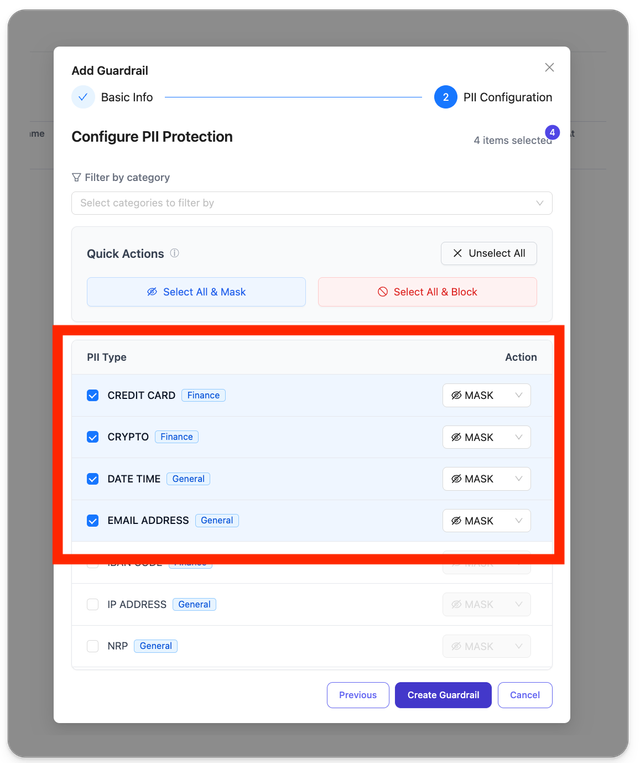
1.2 Configure Entity Types
Now select the entity types you want to mask. See the supported actions here
Define your guardrails under the guardrails section
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "presidio-pii"
litellm_params:
guardrail: presidio # supported values: "aporia", "bedrock", "lakera", "presidio"
mode: "pre_call"
Set the following env vars
export PRESIDIO_ANALYZER_API_BASE="http://localhost:5002"
export PRESIDIO_ANONYMIZER_API_BASE="http://localhost:5001"
Supported values for mode
pre_callRun before LLM call, on inputpost_callRun after LLM call, on input & outputlogging_onlyRun after LLM call, only apply PII Masking before logging to Langfuse, etc. Not on the actual llm api request / response.
2. Start LiteLLM Gateway
litellm --config config.yaml --detailed_debug
3. Test it!
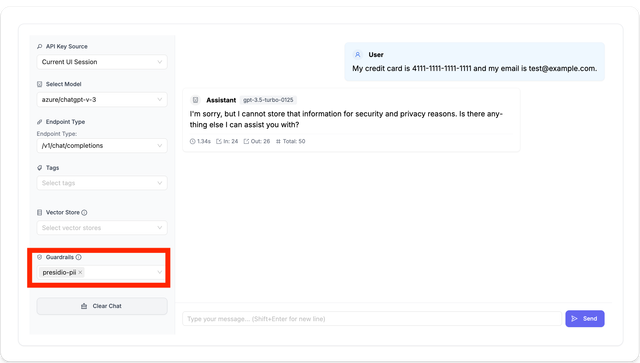
3.1 LiteLLM UI
On the litellm UI, navigate to the 'Test Keys' page, select the guardrail you created and send the following messaged filled with PII data.
My credit card is 4111-1111-1111-1111 and my email is test@example.com.
3.2 Test in code
In order to apply a guardrail for a request send guardrails=["presidio-pii"] in the request body.
Langchain, OpenAI SDK Usage Examples
- Masked PII call
- No PII Call
Expect this to mask Jane Doe since it's PII
curl http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "Hello my name is Jane Doe"}
],
"guardrails": ["presidio-pii"],
}'
Expected response on failure
{
"id": "chatcmpl-A3qSC39K7imjGbZ8xCDacGJZBoTJQ",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "Hello, <PERSON>! How can I assist you today?",
"role": "assistant",
"tool_calls": null,
"function_call": null
}
}
],
"created": 1725479980,
"model": "gpt-3.5-turbo-2024-07-18",
"object": "chat.completion",
"system_fingerprint": "fp_5bd87c427a",
"usage": {
"completion_tokens": 13,
"prompt_tokens": 14,
"total_tokens": 27
},
"service_tier": null
}
curl http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "Hello good morning"}
],
"guardrails": ["presidio-pii"],
}'
Tracing Guardrail requests
Once your guardrail is live in production, you will also be able to trace your guardrail on LiteLLM Logs, Langfuse, Arize Phoenix, etc, all LiteLLM logging integrations.
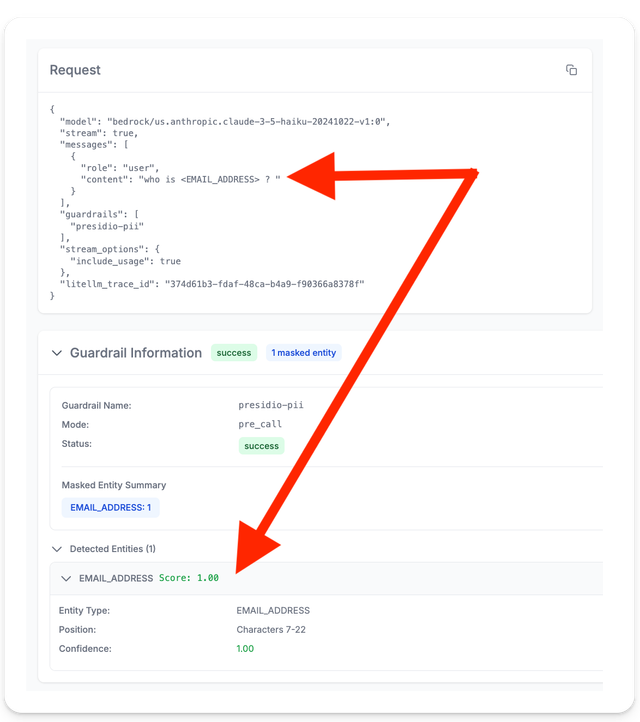
LiteLLM UI
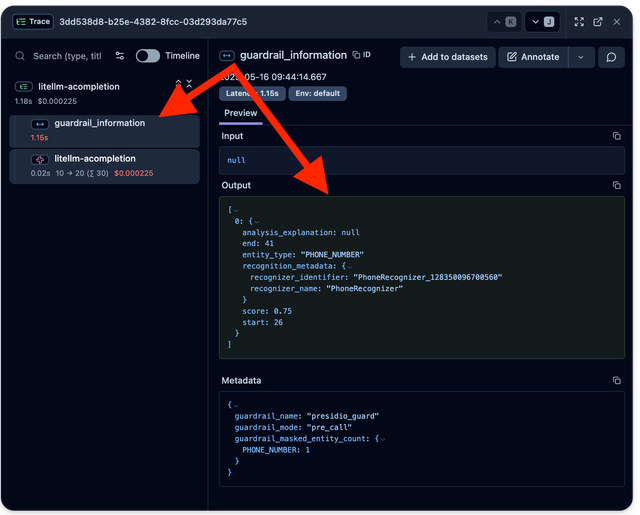
On the LiteLLM logs page you can see that the PII content was masked for this specific request. And you can see detailed tracing for the guardrail. This allows you to monitor entity types masked with their corresponding confidence score and the duration of the guardrail execution.
Langfuse
When connecting Litellm to Langfuse, you can see the guardrail information on the Langfuse Trace.
Entity Type Configuration
You can configure specific entity types for PII detection and decide how to handle each entity type (mask or block).
Configure Entity Types in config.yaml
Define your guardrails with specific entity type configuration:
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "presidio-mask-guard"
litellm_params:
guardrail: presidio
mode: "pre_call"
pii_entities_config:
CREDIT_CARD: "MASK" # Will mask credit card numbers
EMAIL_ADDRESS: "MASK" # Will mask email addresses
- guardrail_name: "presidio-block-guard"
litellm_params:
guardrail: presidio
mode: "pre_call"
pii_entities_config:
CREDIT_CARD: "BLOCK" # Will block requests containing credit card numbers
Supported Entity Types
LiteLLM Supports all Presidio entity types. See the complete list of presidio entity types here.
Supported Actions
For each entity type, you can specify one of the following actions:
MASK: Replace the entity with a placeholder (e.g.,<PERSON>)BLOCK: Block the request entirely if this entity type is detected
Test request with Entity Type Configuration
- Masking PII entities
- Blocking PII entities
When using the masking configuration, entities will be replaced with placeholders:
curl http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "My credit card is 4111-1111-1111-1111 and my email is test@example.com"}
],
"guardrails": ["presidio-mask-guard"]
}'
Example response with masked entities:
{
"id": "chatcmpl-123abc",
"choices": [
{
"message": {
"content": "I can see you provided a <CREDIT_CARD> and an <EMAIL_ADDRESS>. For security reasons, I recommend not sharing this sensitive information.",
"role": "assistant"
},
"index": 0,
"finish_reason": "stop"
}
],
// ... other response fields
}
When using the blocking configuration, requests containing the configured entity types will be blocked completely with an exception:
curl http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "My credit card is 4111-1111-1111-1111"}
],
"guardrails": ["presidio-block-guard"]
}'
When running this request, the proxy will raise a BlockedPiiEntityError exception.
{
"error": {
"message": "Blocked PII entity detected: CREDIT_CARD by Guardrail: presidio-block-guard."
}
}
The exception includes the entity type that was blocked (CREDIT_CARD in this case) and the guardrail name that caused the blocking.
Advanced
Set language per request
The Presidio API supports passing the language param. Here is how to set the language per request
- curl
- OpenAI Python SDK
curl http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "is this credit card number 9283833 correct?"}
],
"guardrails": ["presidio-pre-guard"],
"guardrail_config": {"language": "es"}
}'
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"metadata": {
"guardrails": ["presidio-pre-guard"],
"guardrail_config": {"language": "es"}
}
}
)
print(response)
Output parsing
LLM responses can sometimes contain the masked tokens.
For presidio 'replace' operations, LiteLLM can check the LLM response and replace the masked token with the user-submitted values.
Define your guardrails under the guardrails section
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "presidio-pre-guard"
litellm_params:
guardrail: presidio # supported values: "aporia", "bedrock", "lakera", "presidio"
mode: "pre_call"
output_parse_pii: True
Expected Flow:
User Input: "hello world, my name is Jane Doe. My number is: 034453334"
LLM Input: "hello world, my name is [PERSON]. My number is: [PHONE_NUMBER]"
LLM Response: "Hey [PERSON], nice to meet you!"
User Response: "Hey Jane Doe, nice to meet you!"
Ad Hoc Recognizers
Send ad-hoc recognizers to presidio /analyze by passing a json file to the proxy
Define ad-hoc recognizer on your LiteLLM config.yaml
Define your guardrails under the guardrails section
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "presidio-pre-guard"
litellm_params:
guardrail: presidio # supported values: "aporia", "bedrock", "lakera", "presidio"
mode: "pre_call"
presidio_ad_hoc_recognizers: "./hooks/example_presidio_ad_hoc_recognizer.json"
Set the following env vars
export PRESIDIO_ANALYZER_API_BASE="http://localhost:5002"
export PRESIDIO_ANONYMIZER_API_BASE="http://localhost:5001"
You can see this working, when you run the proxy:
litellm --config /path/to/config.yaml --debug
Make a chat completions request, example:
{
"model": "azure-gpt-3.5",
"messages": [{"role": "user", "content": "John Smith AHV number is 756.3026.0705.92. Zip code: 1334023"}]
}
And search for any log starting with Presidio PII Masking, example:
Presidio PII Masking: Redacted pii message: <PERSON> AHV number is <AHV_NUMBER>. Zip code: <US_DRIVER_LICENSE>
Logging Only
Only apply PII Masking before logging to Langfuse, etc.
Not on the actual llm api request / response.
This is currently only applied for
/chat/completionrequests- on 'success' logging
- Define mode:
logging_onlyon your LiteLLM config.yaml
Define your guardrails under the guardrails section
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "presidio-pre-guard"
litellm_params:
guardrail: presidio # supported values: "aporia", "bedrock", "lakera", "presidio"
mode: "logging_only"
Set the following env vars
export PRESIDIO_ANALYZER_API_BASE="http://localhost:5002"
export PRESIDIO_ANONYMIZER_API_BASE="http://localhost:5001"
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-D '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hi, my name is Jane!"
}
]
}'
Expected Logged Response
Hi, my name is <PERSON>!